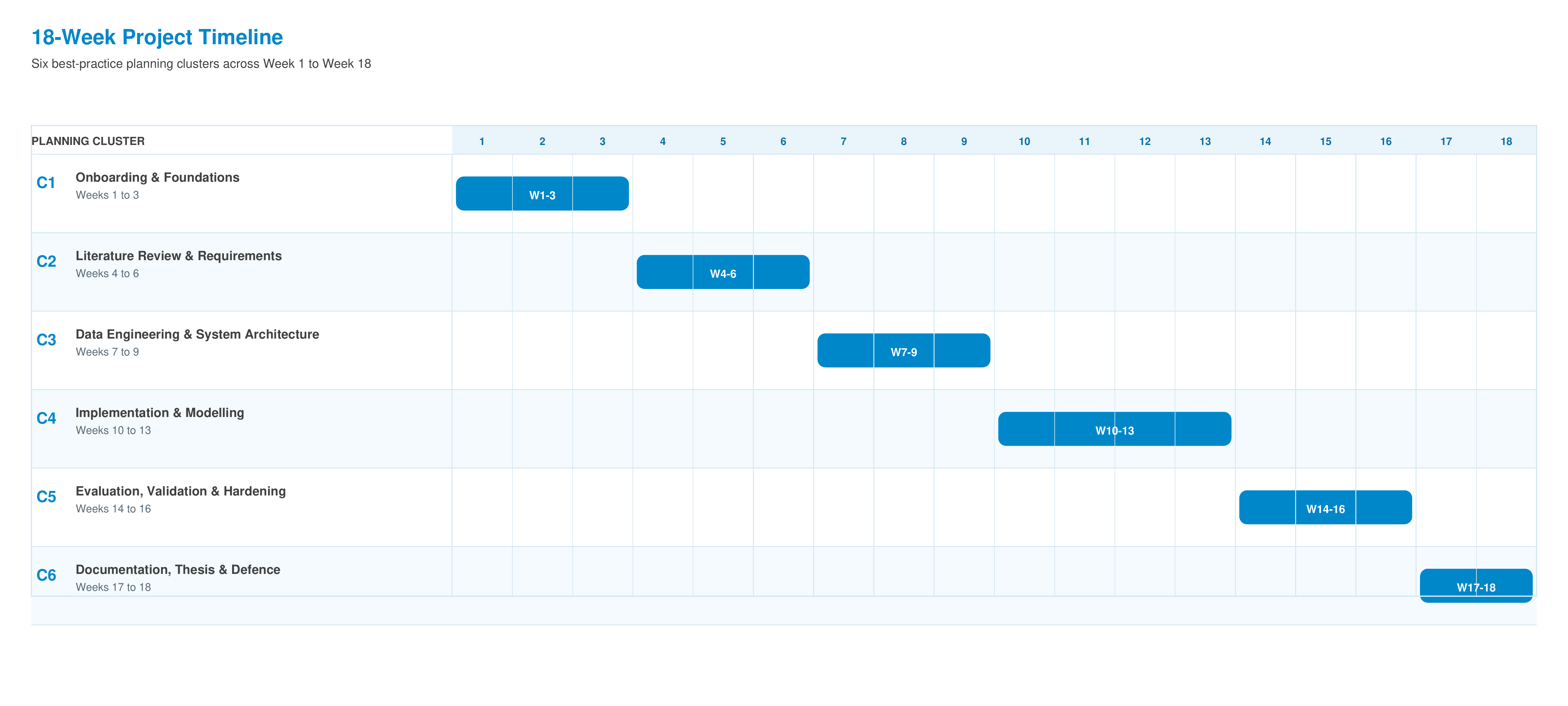
The plan is organised into six best-practice planning
clusters spanning 18 weeks. Each cluster states its focus, key activities and a
milestone that must be reached before the next cluster begins.
Weeks 1-3
Cluster 1 - Onboarding & Foundations
Settle in, set up the working environment, and agree the detailed plan and success criteria with the academic and industrial supervisors.
Key activities
- Onboarding at Graha International: tooling, data-governance and NDA briefing.
- Familiarisation with vehicle telematics, predictive-maintenance concepts and existing Graha assets.
- Set up a reproducible environment: version control, experiment tracking and a containerised workspace.
- Refine scope, success criteria and the detailed 18-week work plan with the supervisor.
Milestone, Approved internship work plan and a running, reproducible development environment.
Weeks 4-6
Cluster 2 - Literature Review & Requirements
Build the scientific foundation through a structured literature review and a precise requirements and evaluation specification.
Key activities
- Structured literature review on RUL/SoH estimation, anomaly detection and causal AI for maintenance.
- Survey of relevant time-series imputation methods and predictive-maintenance datasets.
- Stakeholder and requirements analysis; definition of the core use cases and KPIs.
- Draft the conceptual approach and the evaluation methodology with metrics and baselines.
Milestone, Literature-review report and an agreed requirements and evaluation plan.
Weeks 7-9
Cluster 3 - Data Engineering & System Architecture
Prepare the data assets and design the end-to-end platform architecture.
Key activities
- Acquire, profile and clean the telematics time-series; handle gaps with selected imputation methods.
- Engineer features and labels for anomaly, SoH and RUL tasks.
- Design the platform architecture: ingestion, processing, modelling, explanation and API layers.
- Specify the data model and the interfaces between components.
Milestone, Architecture design document and a prepared, documented dataset and data pipeline.
Weeks 10-13
Cluster 4 - Implementation & Modelling
Implement the platform and the predictive and causal-reasoning models.
Key activities
- Implement the ingestion and processing pipeline as reproducible services.
- Develop and train anomaly-detection and RUL/SoH models; compare statistical, ML and DL approaches.
- Integrate a causal-reasoning layer that links predicted failures to likely root causes.
- Build the explainable maintenance-recommendation component and a minimal review dashboard.
Milestone, Working PdM-platform prototype covering the core anomaly-to-recommendation use case.
Weeks 14-16
Cluster 5 - Evaluation, Validation & Hardening
Evaluate, validate and harden the prototype against domain-informed ground truth.
Key activities
- Run controlled experiments; measure precision, recall, RMSE, R-squared and RUL error.
- Validate causal explanations against literature- and domain-derived ground truth.
- Assess robustness to missing data and noise; check reproducibility of results.
- Iterate on the models and the pipeline based on the evaluation findings.
Milestone, Evaluation report with quantitative results and a validated, hardened prototype.
Weeks 17-18
Cluster 6 - Documentation, Thesis & Final Defence
Consolidate the documentation, draft the thesis material and present the results.
Key activities
- Consolidate code, documentation and reproducibility instructions.
- Write the thesis-ready report covering method, results and limitations.
- Prepare and deliver the final presentation and a live demo.
- Hand over the platform, datasets and backlog of future work to Graha.
Milestone, Final thesis-ready report, final presentation and a complete handover package.